

A central factor in trustworthy autonomous systems is the presence of humans in different stages of an AI system’s deployment cycle - from data curation, to model training, evaluation, and deployment. In real world applications, an AI system requires different experts in each of these stages. For instance, in medical applications, doctors evaluate the decisions made by AI systems but are not well versed with its training. ML engineers can select the best possible models but may not be able to curate unbiased data for these models. Existing human-in-the-loop systems do not account for this variety in the required expertise. Since deep learning based AI systems require many specialized experts, their applicability is limited to only a few non-specialized applications. At OLIVES, we leverage limited experts to train large scalable systems that learn from limited data. We move away from a generic human-in-the-loop framework towards experts-in-the-loop.
1.Active Learning
a.Deployable Active Learning

We propose in this work a novel active learning methodology based on learning reconstruction manifolds with Deep Autoencoders for seismic interpretation. Autoencoders refer to a family of learning models that are trained to reconstruct their inputs. They are designed so that they are only able to reconstruct data sampled from the training distribution, preventing them from regressing to a simple identity mapping. As a useful by-product, they are able to learn the manifold structure of high dimensional data [1, 2]. [3] utilize such a learned manifold for the task of anomaly detection on image datasets by thresholding the distribution of reconstruction error-based scores on input training examples.

Several popular strategies define information content on the model representation of data points directly. However, model representations are infamously unpredictable, especially when few training points are available(a common case in active learning). At OLIVES, we pursue a fundamentally different approach. Instead of utilizing the model representation directly, we define information content on representation shifts. Our definition is not only more accurate in active learning settings, but is also simpler to approximate when few data points are available. In Figure we show examples of highly informative images based on different information content definitions. We see that informative samples as per our definition are significantly harder to distinguish or are ambiguous which implies a higher information content. For instance, our “informative" samples are ambiguous images with complex shapes or ambiguous colors (e.g. the frog image in the top row; third image from the right side). In contrast, the other definitions consider clear images informative that are similar among each other. In GauSS, we combine the definition with efficient sampling techniques to improve the active learning performance on natural images. With FALSE, we gear the definition towards unlabeled data points directly to improve the active learning performance on noisy data.
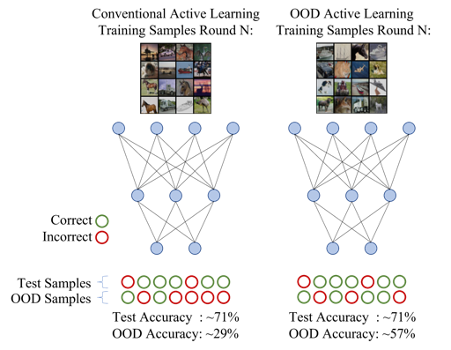
For active learning, robustness properties are not directly apparent from a test set distribution. While two strategies improve test set performance by a similar margin, one strategy may outperform another significantly in out-of-distribution settings. Furthermore, popular approaches are typically not optimized for robustness, and data importance is strictly based on in-distribution settings. In this work, we address active learning robustness with learning dynamics in neural networks. Specifically, we decouple data selection from the model representation by defining sample importance with representation shifts. In each round, we track the frequency of prediction switches on unlabeled data and select the most frequently switching data points for annotation. Within the context of out-of-distribution samples, the step is crucial as model representations are notoriously inaccurate on unknown data samples. We call our approach “Forgetful Active Learning with Switch Events” or FALSE in short. FALSE effectively outperforms popular strategies in out-of-distribution and in-distribution active learning settings

All active learning query strategies operate by estimating the uncertainty with respect to a given sample. For robust uncertainty estimation, we advocate for two stages in a neural network's decision making process. The first is the existing feed-forward inference framework where patterns in given data are sensed and associated with previously learned patterns. The second stage is a slower reflection stage where we ask the network to reflect on its feed-forward decision by considering and evaluating all available choices. Together, we term the two stages as introspective learning. We use gradients of trained neural networks as a measurement of this reflection. A simple three-layered Multi Layer Perceptron is used as the second stage that predicts based on all extracted gradient features. We show that when train and test distributions are dissimilar including during the presence of noise, introspective networks provide accuracy gains in an active learning setting on 5 query strategies.
b.Rethinking Active Learning Frameworks

A single disease can present itself in visually diverse formats across multiple patients. This data diversity is captured within medical metadata but remains un-exploited in existing active learning paradigms. Additionally, medical datasets are widely imbalanced both across classes and patients. This ultimately results in existing methods training models without properly accounting for one or more patient disease manifestations from whom there is less data. We develop a framework [1] that incorporates clinical insights into the sample selection process of active learning that can be incorporated with existing algorithms. The framework captures diverse disease manifestations from patients to improve generalization performance of OCT classification. We also demonstrate that active learning paradigms developed for natural images are insufficient for handling medical data [2].

At OLIVES, we view video active learning from a cost-centered perspective. We present the first active learning dataset FOCAL for sequential cost analysis on video sequences for autonomous driving settings [1]. It consists of a plethora of real-world scenarios that include 149 unique sequences, 109 000 frames, and79 unique scenes across a variety of weather, lighting, and seasonal conditions. In our analysis, we compare popular active learning approaches in singular and sequential setting. For sequential settings, algorithms largely neglect cost information and scale linearly to randomly sampling individual data points; the naïve baseline.
iii.Continual Active Learning for OCT Scans
Previous work has focused on different query strategies for active learning using OCT scans. In particular, [1] improved generalization performance for OCT disease classification by partitioning the training pool by patient identity and sampling based upon this partition, demonstrating how different query strategies can influence model results. Such an approach can be taken for this project, where the query strategies investigated can include using standard query strategies (like random, entropy, etc.) and/or incorporating clinical biomarkers into the query strategy. In addition, our method must combat regression, and the first step in this process is to understand and model the domain shift across visits. Afterwards, we will use a metric, such as the negative fliprate (NFR), to evaluate how much the model is forgetting.